Although there has been a proliferation of biological datasets made available in recent years, often this information isn’t machine readable, making it hard for things like Google Dataset Search to find and index them. In this series of blog posts, we’ll outline how we are working to make datasets that our collaborators generate and open data more findable, accessible, interoperable, and reusable, as well as tools that we’ve developed to make it easier to share data. In this post we discuss schemas and the rationale behind the schema playground in the Data Discovery Engine.
What Are Schemas?
We previously gave a general introduction on building a resource sharing site with the tools developed by the Su and Wu labs, but to understand the need for the tools, it’s important to understand schemas. In psychology, a schema is a pre-existing cognitive framework or pattern of thought with which you categorize and interpret new information. In theory, this allows us to process new information more quickly, but predisposes us to errors due to stereotypes and bias. In the data world, you can think of schemas as a means for allowing search engines to consume, process, and interpret information very quickly so that more meaningful results are returned.
If you’ve ever googled a movie or a recipe, you might notice that you sometimes get specialized infoboxed results.
For example if you search for a ‘coconut butter fudge’, the google search engine may return a special type of result (the recipe) which is presented differently and may include special information like prep time, ingredients, ratings, images, and the website that the recipe comes from.
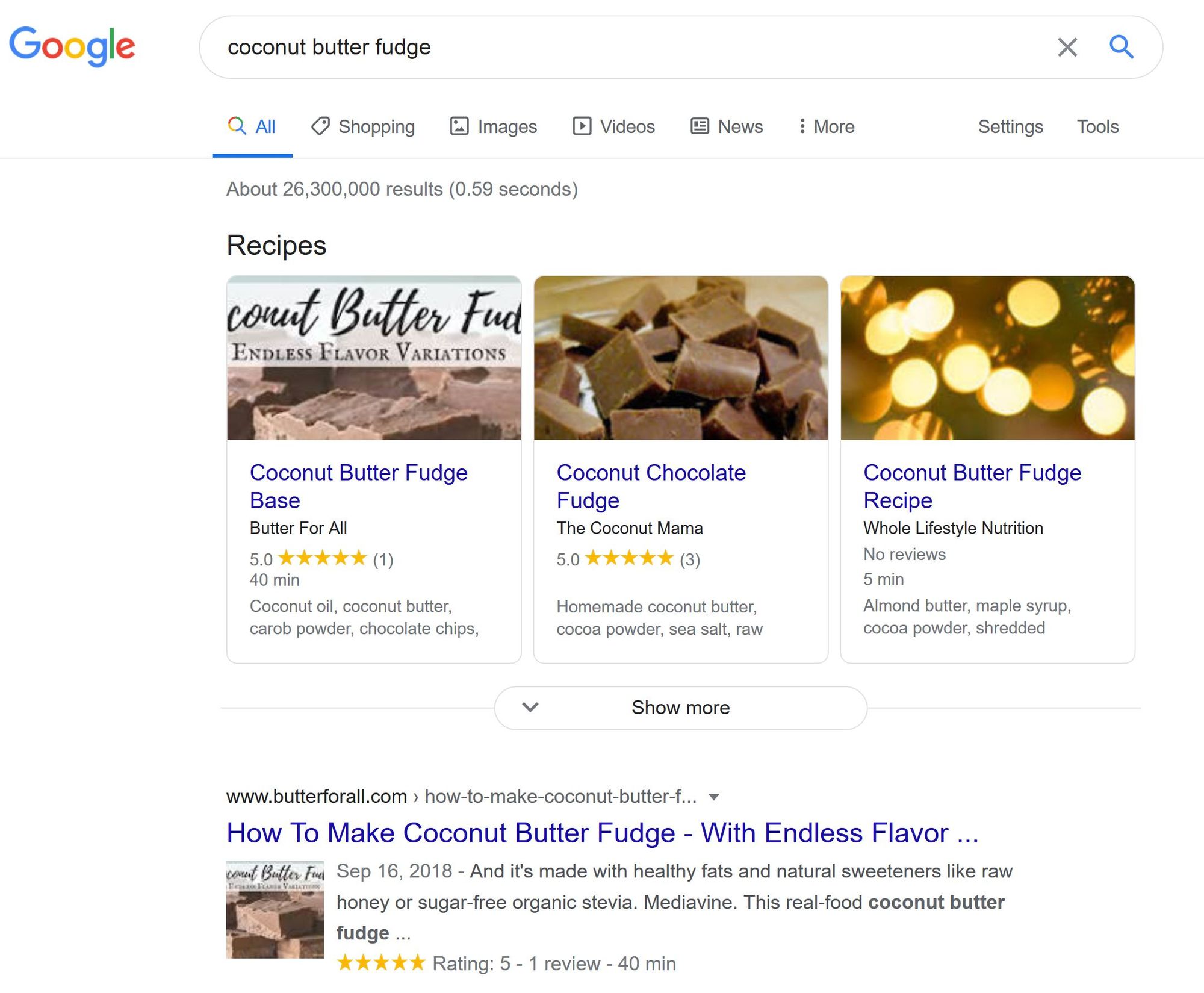
As seen in this example, these recipes come from different websites, yet they are presented in a manner which allows the user to easily compare them by the specialized information. If the user was pressed for time, maybe the 5 minute recipe would be the one of greatest interest. If the user wanted to attempt a recipe that others have rated highly, then maybe the one with 5 stars from 3 reviewers would be preferred.
The reason the search engine can return consistent information from different websites so that the user can better find what they’re looking for is because the metadata for these recipes are structured in a schema-compatible manner.
Simply put, a consortium from the big search engine companies (Google, Yahoo, Bing) came up with a standard way of structuring metadata so that the search engines could provide better results. This standard can be found at https://schema.org.
Because there are many different types of information, there are a lot of different schemas (or ways information can be structured) which depend on the type of information.
For example, a recipe would be one type (or schema since schemas are type-dependent) of information; a scholarly article would be another type. For each type (or schema), there will be a different set of properties. For example, a recipe might have a ‘ingredients’ property, but a scholarly article would not. In contrast, a scholarly article might have a starting page, while a recipe would not.
But wait, couldn’t a recipe have a starting page if it were published in a recipe book?
Yes, absolutely! This is one reason why schemas are inherently very flexible! In fact, they’re so flexible, you could find ways to nest, couple, and structure metadata in ways that may ultimately confuse a search engine or render your metadata less meaningful. You could also create new properties which would be meaningful only to you, but would be un-interpretable otherwise.
This is why other schema-creating consortia exist–and if you’re interested in schemas in the biological science space, you should have a look at bioschemas.org.
In our next post we’ll discuss the schema playground of the Data Discovery Engine that was created to make it easier to adapt existing schemas to specific use cases.